ExitProcess
El caso es que estos últimos días he estado dándole vueltas a una idea
interesante para programar un juego, de modo que hoy he estado revisando
4k y 4kGL, pensando en la posibilidad de usar uno de ellos como
punto de partida.
La idea me gusta lo bastante para haber decidido implementarlo de forma
portable. Probablemente usaré C++ con SDL o Haxe, así que el tema
de hacerlo sobre la API de Windows queda descartado.
Sin embargo, durante el repaso he visto una cosa que no recordaba
y que me ha llamado la atención. El código relevante es el siguiente:
void
Shutdown (UINT uExitCode) {
...
// without WinMainCRTStartup() we must exit the process ourselves:
ExitProcess(uExitCode);
}
¿Uh? ¿Por qué se llama manualmente a ExitProcess?
4k y 4kGL están pensados para ser usados sin librería de C. En un programa
normal que sí usa libc, el punto de entrada real no es "WinMain", sino
"WinMainCRTStartup", que se encarga de ejecutar primero WinMain
y luego ExitProcess.
La pregunta se reduce entonces a: ¿Por qué hace falta llamar a ExitProcess?
La respuesta está en la siguiente imagen, tomada de Process Explorer:
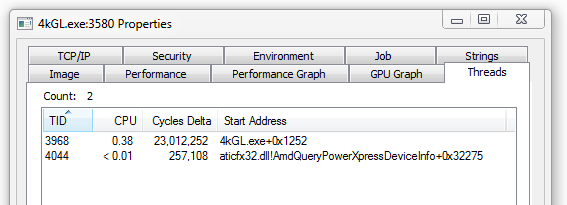
Un proceso de Windows no se termina hasta que todos sus hilos terminan.
4kGL en realidad no usa uno, sino dos hilos. El segundo procede del driver
de ATI y se lanza de manera automática al utilizar OpenGL.
Cómo no aprender a programar
Si me preguntases, hace un tiempo habría dicho que una buena introducción
práctica a la programación sería tratar de resolver los problemas planteados
en los ejercicios del Proyecto Euler. Escoger un lenguaje, por ejemplo
Scheme o Python, e ir resolviendo.
A día de hoy mi respuesta sería bien distinta.
El primer problema consiste en calcular la suma de todos los números naturales
menores de 1000 que sean múltiplos de 3 o 5. Una posible solución, escrita
en Racket, es la siguiente:
#lang racket/base
(define (multiple-of-3-or-5? n)
(or (zero? (modulo n 3))
(zero? (modulo n 5))))
(for/fold ([sum 0])
([i (in-range 1000)]
#:when (multiple-of-3-or-5? i))
(+ sum i))
Niklaus Wirth dijo allá por 1976 que "algoritmos + datos = programas".
Si analizamos el texto anterior vemos que hay algoritmos, expresados en
forma de función: "multiple-of-3-or-5?", y vemos que hay datos, como el
rango de números de 1 a 1000. ¿Podemos decir entonces que es un programa?
Claramente podemos, pero sin embargo no se parece gran cosa a un programa "real".
Cuando estudié informática, me enseñaron a programar de un modo similar. Nos
proponían pequeños ejercicios, puzles, cosas como: "encuentra el elemento X
en la lista enlazada Y" o "ordena este vector de N elementos". Creo que es una
manera horrible de aprender.
El otro 90%
La pregunta clave es: ¿qué falta aquí?.
Cada vez estoy más convencido de que la parte difícil de la programación no es
la algoritmia. Diría que el 10% de un programa es pura algoritmia. El otro
90% es control de errores, I/O a archivos o sockets, localización tanto de
lenguaje como de moneda o huso horario, codificación (unicode, shift-jis, etc),
aprovechamiento de recursos (múltiples procesadores, memoria), diseño modular
en componentes y librerías, interactuar con programas y librerías escritas
por otras personas, portabilidad entre arquitecturas, etc...
No hay nada de eso en el programa anterior.
Crear algo en el laboratorio es fácil, es un entorno seguro sin agentes
externos. Todo está bajo un estricto control. En la vida real, ni siquiera
el enunciado del problema está completamente especificado. Los requerimientos
cambian día a día.
La mayoría de problemas importantes en algoritmia ya han sido resueltos. Las
matemáticas son exactas. Sin embargo, se discute día a día sobre patrones y
métodos para estructurar el código que hagan más sencilla su comprensión. Se
discute sobre dinámicas de trabajo en equipo que permitan a las personas
cooperar más eficientemente.
¿Quieres aprender a programar? Lee el código de un programa que uses día a día
y analíza su diseño. Trata de modificarlo. Ignora "qué" e intenta entender el
porqué de cada decisión y sus consecuencias.
Más detalles que importan
En el primer post de este blog comentaba acerca de un detalle de Thunderbird
con respecto a su tratamiento de archivos adjuntos que me gustó. Este post
es un ejemplo de lo contrario, una lista de pequeños bugs o comportamientos
irritantes en programas que uso a menudo.
Estos bugs son especialmente molestos porque me los he encontrado en programas
que usan miles de personas todos los días y - a priori - no parecen difíciles
de solucionar.
Windows 7 - redimensionando la barra de estado
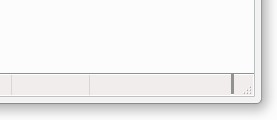
Redimensionar una ventana del explorador que tenga una barra de estado causa
la aparición de una minúscula línea negra vertical en el borde inferior derecho.
Hasta donde he podido ver, ocurre con cualquier tarjeta gráfica e independientemente
de estar usando Aero o el tema básico de escritorio.
Curiosamente, el bug solo ocurre si la ventana se redimensiona verticalmente.
Tras maximizar, minimizar o redimensionar la ventana horizontalmente, la línea
negra desaparece. No me acordé de probar si este problema existe también en
Windows 8.
SMPlayer - por defecto, el ecualizador no funciona
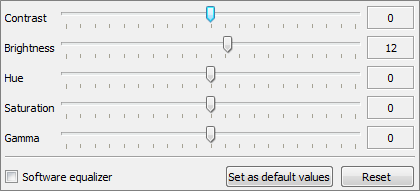
SMPlayer es tranquilamente uno de los mejores reproductores de video para Windows.
Incluye codecs de serie, soporta subtítulos, múltiples pistas de audio o menús de
DVD, etc...
Sin embargo, con la configuración que viene por defecto, no funciona ninguno
de los controles del ecualizador.
Cambiar la salida de video de Direct3D a OpenGL funciona, pero desactiva Aero.
La forma de tener ambos a la vez es marcar esa casilla que reza: "Software equalizer".
No he notado pérdida de rendimiento alguna tras marcarla.
Racket - no se puede copiar/pegar código en la consola interactiva
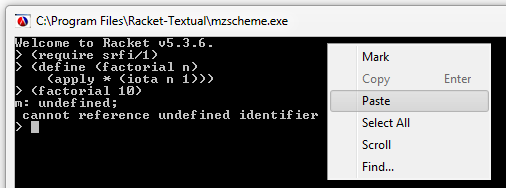
Tenía que incluír una sobre programación.
Por algún motivo, Racket no lee correctamente código que se haya pegado directamente
en su consola interactiva. Insiste en añadir carácteres como "m" y "R" al código. De
hecho lo peor es que a menudo parece funcionar y luego se rompe en el momento más
inesperado.
Este bug ya ocurría cuando Racket aún se llamaba mzscheme.
7-zip - menú contextual
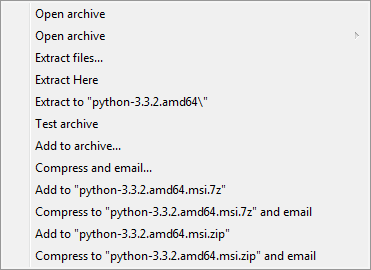
¿Necesito decir más? Es un ejemplo perfecto de "una imagen vale más que mil palabras".
El menú contextual integrado con el explorador de Windows que ofrece 7-zip es útil
pero la configuración por defecto es ridícula.
Un elemento tiene submenú: "Open Archive", mientras que el resto de elementos no
y simplemente aparecen repetidos, con ligeras variaciones según lo que hacen. Ni
siquiera están ordenados según su función.
En mi opinión, un diseño más lógico sería algo tipo: "Open, Add, Compress, Extract,
Test" todos con submenú y dentro de cada uno las opciones particulares específicas
para cada elemento.
Paint .NET - control de zoom

Una cosa que me gusta de la interfaz de Paint.NET es que sus desplegables incluyen
las opciones más comunes, pero al mismo tiempo permiten escribir para poder elegir
valores más concretos.
En el caso del zoom, aparecen valores como 33%, 50%, 66%, 100%, 200%, etc...
Supongamos que quiero 120%, como en la imagen. Mi primer ímpetu es escribir el número
y pulsar enter para aplicar los cambios. Ésto funciona perfectamente y el nuevo zoom
se aplica, excepto que cualquier seleccion actual en la imagen se pierde nada más
pulsar la tecla.
El modo de aplicar un zoom específico pero manteniendo cualquier selección implica
escribir el número y después hacer click en otra parte de la interfaz, sin pulsar enter,
para cambiar el foco del control activo. Ésto no es suficientemente intuitivo.
Dropbox - un instalador poco educado
Aquí no hay foto. El instalador que usa Dropbox decide por su cuenta que es buena
idea matar el proceso "explorer.exe" (el explorador de Windows), para asegurarse de
poder activar su integración.
El problema de hacer ésto es que cualquier operación con el explorador en ese momento
se interrumpe sin más. ¿Estabas moviendo 40 GB? pues ánimo, ahora tienes parte de los
archivos en el origen y parte en el destino, apáñate.
Respuesta inmediata con múltiples hilos
La idea básica de MultiHash consiste en calcular múltiples algoritmos,
como md5, sha1, etc..., de múltiples archivos, leyendo cada archivo
una sola vez.
Aunque ésto ya mejora la eficiencia notablemente (con respecto a las
herramientas en coreutils), podemos hacerlo mejor. La idea es dividir
el trabajo en tareas, donde cada tarea calcula todos los algoritmos para
un archivo. Una serie de hilos ejecuta estas tareas a la vez. En un equipo
con 2 o más procesadores y un disco duro rápido (SSD, RAID)
la diferencia de velocidad es considerable.
Un problema interesante cuando se trabaja con hilos (aparte de sincronización)
es cómo presentar los resultados al usuario, tan pronto como estén listos y
en el orden correcto, independientemente de los hilos que acaben antes o que
aún se estén ejecutando. El objetivo, desde un punto de vista de interfaz, es
ocultar el hecho de que se están usando hilos, que debería ser un detalle
interno, y dar la impresión de un programa secuencial normal.
El resto de este post trata sobre cómo hacerlo en Python. Es esencialmente el
mismo código que usa MultiHash, simplificado a modo de ejemplo.
Hilos y tareas
El primer paso es obvio, crear una subclase de Thread que toma tareas de una
Queue, las ejecuta y añade el resultado (que se guarda en la propia tarea)
a otra Queue. Entenderemos como tarea cualquier objeto que implemente un
método "run()".
class Worker(Thread):
def __init__(self, todo, done):
super().__init__()
self.todo = todo
self.done = done
self.daemon = True
self.start()
def run(self):
while True:
task = self.todo.get()
task.run()
self.done.put(task)
self.todo.task_done()
Las tareas simplemente calcularán números de fibonacci usando un algoritmo
recursivo (y terriblemente ineficiente) guardando el resultado en una
propiedad de la propia tarea:
def fib(n):
if n < 2:
return 1
else:
return fib(n - 1) + fib(n - 2)
class FibTask(object):
def __init__(self, number):
self.number = number
def run(self):
self.result = fib(self.number)
Finalmente, un ThreadPool empezará a ejecutar tareas usando tantos hilos
como le pidamos al inicializar:
class ThreadPool(object):
def __init__(self, threads):
self.threads = threads
self.tasks = []
self.results = set()
self.todo = Queue()
self.done = Queue()
def start(self, tasks):
""" Start computing tasks. """
self.tasks = tasks
for task in self.tasks:
self.todo.put(task)
for x in range(self.threads):
Worker(self.todo, self.done)
Esperando a las tareas terminadas
Aquí viene la parte interesante. El objeto que representa cada tarea
puede ser su propio identificador. La propiedad ".tasks" de ThreadPool
mantiene el orden inicial de las tareas. La propiedad ".results" contendrá
las tareas completadas.
Podemos añadir un método que itera el orden inicial y devuelve cada
tarea completada tan pronto como se encuentre en los resultados:
class ThreadPool(object):
...
def poll_completed_tasks(self):
"""
Yield the computed tasks, in the order specified when 'start(tasks)'
was called, as soon as they are finished.
"""
for task in self.tasks:
while True:
if task in self.results:
yield task
break
else:
self.wait_for_task()
# at this point, all the tasks are completed:
self.todo.join()
Donde wait_for_task() está implementado de la siguiente manera:
class ThreadPool(object):
...
def wait_for_task(self):
""" Wait for one task to complete. """
while True:
try:
task = self.done.get(block = False)
self.results.add(task)
break
# give tasks processor time:
except queue.Empty:
time.sleep(0.1)
Intentamos tomar una tarea completada, sin bloquear. Si no lo conseguimos,
dormimos durante 0.1 segundos y lo intentamos de nuevo, hasta que una tarea
ha sido completada.
Ejemplo de uso:
def main():
cpus = cpu_count()
pool = ThreadPool(cpus)
tasks = [FibTask(n) for n in range(1, 33)]
tasks += [FibTask(n) for n in reversed(range(1, 33))]
pool.start(tasks)
# should print the results in order
# first from 1 to 32, then from 32 to 1:
for task in pool.poll_completed_tasks():
print('fib({0.number}): {0.result}'.format(task), flush = True)
if __name__ == '__main__':
try:
main()
except KeyboardInterrupt:
pass
Aunque algunas tareas terminen antes que otras, los resultados se mostrarán
en orden, tan pronto como sea factible. Control + C debe detener la ejecución
correctamente.
El código completo del ejemplo está disponible aquí.
Detalles que importan
Si uno observa lo suficiente, le es fácil encontrar pegas al software que usa.
No cosas grandes (que también), me refiero a detalles minúsculos pero importantes
que solo se ven de cerca. Ese tipo de cosas que hacen decir "pues vaya rollo".
Es menos habitual encontrar algo que provoque la sensación contraria. Una
característica que no era realmente necesaria pero que su inclusión es útil
y te hace sonreír.
He aquí un ejemplo.
Añadiendo archivos adjuntos en Thunderbird
Hace poco, debido a un bug en Claws Mail pasé a usar Thunderbird.
Mientras escribía el primer email, me encontré el siguiente mensaje:
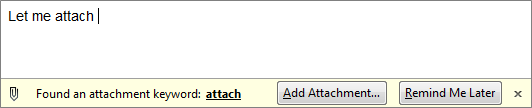
Detecta mientras escribo que mi intención es añadir un archivo al correo
actual y me ofrece una manera simple de hacerlo, pero sin interrumpir.
Lo más importante: el foco de la aplicación se mantiene en el correo,
sin distracciones ni popup molestos.