Cosas que aprendí de... MultiHash
MultiHash es un pequeño programa escrito en Python que calcula algoritmos
como md5, sha1, sha256 etc... al estilo de md5sum o sha1sum
de coreutils.
Su principal baza es que puede calcular múltiples algoritmos (de ahí el nombre)
leyendo cada archivo una sola vez. Además, puede dividir el trabajo en hilos,
donde cada hilo lee y calcula los algoritmos para un archivo. Es posible
ejecutar tantos hilos como se desee de manera concurrente, aunque lo usual
es utilizar el mismo número que procesadores hay en el sistema.
Este post será corto porque la parte más interesante, de la que más aprendí,
es sin duda el threadpool y ya hice en su día un post sobre ello,
detallando todo el proceso. Aún así, alguna que otra cosa sí puedo contar...
Python y múltiples hilos
A cualquiera que conozca Python un poco, le extrañará que lo haya escogido para
crear MultiHash. Un estigma comúnmente asociado a Python es que su soporte para
threads es horrible debido al GIL.
Yo no estoy de acuerdo.
El GIL o "Global Interpreter Lock" es un mecanismo que solo permite ejecutar
código Python (bytecode) en un thread a la vez. Es imposible aprovechar
múltiples procesadores con código Python puro.
La palabra importante es "puro". Las extensiones escritas en C (o en Cython)
pueden saltarse esta limitación, permitiendo usar tantos threads como sea
necesario. Si uno mira el código de hashlib.h, la cabecera principal de
la librería que MultiHash usa para calcular los algoritmos, encuentra:
/*
* Helper code to synchronize access to the hash object when the GIL is
* released around a CPU consuming hashlib operation. All code paths that
* access a mutable part of obj must be enclosed in a ENTER_HASHLIB /
* LEAVE_HASHLIB block or explicitly acquire and release the lock inside
* a PY_BEGIN / END_ALLOW_THREADS block if they wish to release the GIL for
* an operation.
*/
#ifdef WITH_THREAD
#include "pythread.h"
#define ENTER_HASHLIB(obj) \
if ((obj)->lock) { \
if (!PyThread_acquire_lock((obj)->lock, 0)) { \
Py_BEGIN_ALLOW_THREADS \
PyThread_acquire_lock((obj)->lock, 1); \
Py_END_ALLOW_THREADS \
} \
}
#define LEAVE_HASHLIB(obj) \
if ((obj)->lock) { \
PyThread_release_lock((obj)->lock); \
}
#else
#define ENTER_HASHLIB(obj)
#define LEAVE_HASHLIB(obj)
#endif
Todos los algoritmos usan ENTER_HASHLIB() para saltarse el GIL antes de
empezar sus cálculos, así que es perfectamente viable usar threads. El
rendimiento de MultiHash escala sin problemas a tantos procesadores como
haya en el sistema.
Además, según mi experiencia, hay dos tipos de programas:
-
Aquellos en los que el rendimiento "no importa", porque están limitados
por otros factores, como la velocidad de transmisión de datos en un socket.
Un ejemplo de esto es un cliente de IRC o el comando "ping". En estos casos
el rendimiento de Python es más que suficiente.
-
Aquellos en los que hasta el último segundo importa, como un raytracer o
procesamiento de imágenes. En estos casos, con o sin GIL, Python nunca te
daría una velocidad aceptable, así que no queda otra que escribir la parte
importante en un lenguaje como C.
Aún así, sí existen modos de saltarse el GIL con código Python puro, como
usar multiprocessing, que usa subprocesos en lugar de threads.
Texto o binario
Cuando se abre un archivo, se puede abrir en modo texto o en modo binario.
Increíblemente, md5sum, sha1sum, etc... abren sus archivos en modo texto
por defecto.
Linux (y en general Unix), no distingue entre archivos de texto y binario,
pero Windows sí y el resultado de un checksum es diferente. Esto ha llevado
a problemas de compatibilidad en sistemas como Cygwin (o en ports
de md5sum a Windows).
MultiHash siempre lee los archivos en modo binario, que es lo único que tiene
sentido para calcular hashes. Por compatibilidad con las herramientas de
coreutils, su salida añade un asterisco '*' antes del nombre de cada fichero.
Conclusiones
En el último postmortem escribía que HexPaste fue creado por necesidad, porque
no había una herramienta que me permitiese pegar poemas línea a línea en IRC.
MultiHash sin embargo, nació de una idea muy simple: "¿Y si calculamos todos los
algoritmos a la vez?". La intención es aplicarlo a cosas como las ISOs de Debian
u otras distribuciones, que siempre incluyen todos los checksum.
Ha sido también mi primera experiencia creando un programa multihilo y la verdad
es que no me puedo quejar, ha sido divertido. Es un poco trampa, porque dado que
todos los hilos son completamente independientes entre sí, no me he tenido que
pegar con mutex y las cosas realmente complicadas.
Repositorios en Github: MultiHash
Cosas que aprendí de... HexPaste
Siempre me ha gustado la literatura, especialmente la poesía. Por eso, a veces
comparto aquí las cosillas que voy escribiendo. También por eso, el primer
canal de IRC al que entré hace años era de poesía: #poesia en IRC-Hispano.
Aunque ahora es muy diferente, por aquel entonces el canal era un pequeño y
acogedor grupo de amigos compartiendo poemas. Lorca, Miguel Hernández, Rafael
De León... un poco de todo. De todo esto hace unos 12 años.
Lo primero que aprendí es que copiar y pegar un poema a mano no es práctico.
La mayoría de usuarios (yo incluído) usábamos un comando de mIRC que se
llama /play para recitar.
Tiene esta pinta:
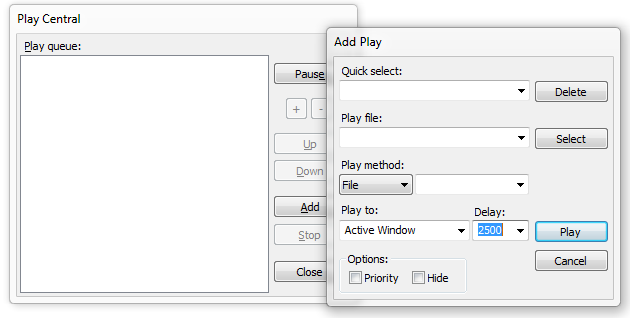
Lo más útil es que permite especificar un retardo entre líneas de modo que el
poema vaya apareciendo poco a poco y sea cómodo de leer. Así fue como recité
durante años, hasta que llegó un momento en el que quise probar linux y otros
sistemas operativos.
XChat
Lo más parecido a mIRC para linux es XChat. XChat está bien pero no tiene
nada que se parezca al comando /play, así que sin un plugin para poder recitar
volví a tener que recitar los poemas a mano.
Aunque por aquel entonces tampoco tenía mucha idea de programación, decidí intentar
hacer mi propio plugin para XChat que me permitiese recitar poemas en el canal.
Este fue el origen de HexPaste, que es quizá el programa más antiguo (al menos
sus raíces) de todos los que tengo actualmente en Github.
En su momento, escribí ese plugin en Perl y era extremadamente limitado.
Por no poder no podías ni cambiar de pestaña durante un recitado porque siempre
pegaba el texto a la pestaña actualmente activa.
HexChat y HexPaste
Tras unos cuantos años un poco alejado del canal y sus quehaceres, al final volví.
Supongo que el gusanillo de la poesía está siempre ahí. XChat es ahora un proyecto
fantasma (su última actualización es de hace 5 años) y lo que se lleva es HexChat.
Con más conocimientos, decidí reescribir aquel plugin que había hecho en Perl pero
en Python, mucho más robusto y práctico que antaño. Esta vez, añadiría cosas como
poder recitar en múltiples canales a la vez o que sustituyese líneas en blanco en
un archivo por espacios.
HexPaste es en realidad un programa muy simple. Son unas 350 líneas de código
escritas en Python 3. No hubo grandes problemas durante su desarrollo en cuestión
de arquitectura porque tenía bastante claro lo que buscaba.
El mayor problema fue la API para Python de HexChat. Esta API es poco más que
la API de C pero expuesta a Python, sin ningún tipo de ayuda o intención por hacerla
más idiomática a lo que un programador de Python esperaría:
-
Muchos campos son bitfields.
-
Un "contexto" (canal, query) del tipo que hexchat.get_context() devuelve
no es "hashable" y no se puede usar como clave en un diccionario de Python.
-
Muchas veces HexChat se come las excepciones, sin mostrar mensaje de error alguno.
-
Como se usan timers en lugar de threads es extremadamente fácil hacer que HexChat
pete completamente debido a un bug y tengas que reabrirlo.
Tengo la teoría de que es esta API la culpable de que la mayoría de plugins para
HexChat (y antes XChat) sean juguetes comparados con los que existen para mIRC
y otros clientes de IRC.
Por lo demás, tacos mediante, HexPaste fue más o menos fácil de crear. Y fácil
de portar de Python 2 a Python 3. Es uno de los proyectos que más he usado de
los que he hecho.
Conclusiones
Creo que la lección más importante que he aprendido de HexPaste es que la necesidad
es una buena compañera de proyectos.
Muchos programas parten de ideas interesantes a explorar, donde hay que hacer una
mayor labor de diseño que de programación. Este parte de necesitar algo que no existe
para aliviar la incomodidad de copiar/pegar a mano. Hay pocas satisfacciones mejores
que usar diaramente algo que has creado tú.
Repositorios en Github: HexPaste
Cosas que aprendí de... Frozen-Blog
Cuando empecé con esto de crear proyectos y compartirlos online, pensaba
que una vez tuviese suficientes, crearía un blog donde ir contando mis
progresos. Las cosas que salieron bien, las que no tan bien, decisiones
de diseño, pequeños detalles interesantes...
Una vez llegó el momento, no tenía muy claro qué hacer. Sabía que quería algo
simple, que no necesite una base de datos aparte (como Wordpress) e
independiente de servicios online concretos (como Blogger).
Github y Jekyll
Afortunadamente, pronto encontré una alternativa. Entre las muchas cosas
que ofrece Github, está Jekyll: un generador de blogs estáticos.
El resultado (el HTML que Jekyll genera) puede alojarse en el propio Github.
Como no es oro todo lo que reluce... tampoco tardé en encontrar problemas:
-
Pésimo soporte para Windows. Ha habido ocasiones en que Jekyll ha estado
meses sin funcionar por culpa de algún bug en las librerías que usa.
A día de hoy Windows ni siquiera está soportado oficialmente.
-
El sistema de plantillas: Liquid es extremadamente limitado.
Hasta Jekyll 2.2.0 era imposible ordenar las categorías alfabéticamente.
-
En modo interactivo, Jekyll regenera la web entera con cada cambio.
En cuanto tienes un número de posts considerable (digamos 200) esto
es muy lento e ineficiente.
-
Aunque Jekyll está escrito en Ruby, depende de Python y Pygments para tener
sintaxis de colores decente. Con el tiempo, se añadió soporte para Rouge,
que soporta menos lenguajes, pero no necesita Python.
Tras descartar Jekyll, me puse a buscar otros generadores parecidos. Recuerdo
que probé unos diez. Muchos tenían serias limitaciones o eran demasiado
complicados. Aunque había alguno prometedor (por ejemplo Pelican) decidí
crear uno propio. Lo que no sabía es que terminaría escribiendo no uno, sino
cuatro generadores distintos, cada uno con sus ventajas y desventajas.
Frozen-Flask
Lo que me llevó a crear Frozen-Blog, fue un post de Nicolas Perriault en el
que utiliza Flask y Frozen-Flask para generar un blog simple.
El código completo son unas 35 líneas de Python.
Pensé: ¿Y si generalizamos esta idea? ¿Y si le añado todo lo que se espera de
un generador estático? No tardé en añadir categorías (múltiples por post),
paginación, soporte para sintaxis de colores, configuración externa y todo lo
que fui necesitando.
Pronto me di cuenta de que Flask-FlatPages era un tanto limitado.
En particular, está ligado a Flask. Es imposible crear múltiples instancias
en una sola aplicación. Por eso creé también MetaFiles, un fork de
Flask-FlatPages que es independiente de Flask, Jinja2 o cualquier librería
externa y que usé en Frozen-Blog tanto para posts como para páginas.
Una curiosidad sobre Flask es que sus archivos de configuración no son JSON
o INI, sino código Python. En Frozen-Blog aprovecho esto para poder hacer
cosas como la siguiente:
# cambia el formato de fecha/hora a castellano en todo el blog:
import locale
locale.setlocale(locale.LC_TIME, 'spanish')
HTML y CSS
Con el generador listo, solo faltaba un tema simple y elegante para presentar
el blog. Creo que puedo decir sin miedo a equivocarme que esta fue la parte
más difícil de todo el proyecto.
HTML5 y CSS3 son relativamente simples, pero cada navegador tiene la manía
de interpretarlos de modo diferente. El tema que escribí para Frozen-Blog
funciona en cualquier navegador, hasta en IE6 o en navegadores de texto
para consola (como lynx). También permite hacer zoom correctamente sin
deformar la maquetación del contenido.
La lección más importante en este sentido fue que es imposible testear en
suficientes entornos sin máquinas virtuales o sin hacer uso de herramientas
online como BrowserStack o los validadores de HTML y CSS de la W3C.
Conclusiones
Estoy satisfecho con el resultado y sobre todo con las librerías que he usado
para llegar a él. Flask y Jinja 2 son excelentes. Todo lo que hace
Armin Ronacher suele serlo.
Por poner un "pero": este proyecto me hace darme cuenta de lo complicadas
que son la mayoría de páginas web o blogs que hay por ahí. La gente se
sorprende cuando abre un blog y tarda menos de 1 segundo en cargar. Yo opino
que esto debería ser la norma y no la excepción. ¿Cuánto de todo lo que ha
cargado es contenido? ¿Cuánto es realmente necesario?
Repositorios en Github: Frozen-Blog - MetaFiles
Cosas que aprendí de... EmbedDIBits
Aunque tras escribir Sokoban decidí crear un framework, 4k no fue el único
proyecto que nació como resultado del juego. Durante el desarrollo de 4k,
empecé dos proyectos más, dos utilidades, ambas escritas en Python.
La primera de las utilidades se llama EmbedXSB. Traduce niveles de Sokoban
en formato XSB a cabeceras de C. Como la cabecera resultado es específica
para Sokoban 4k (diseñada para ocupar lo menos posible), no llegué nunca
a limpiar y mejorar el programa y publicarlo en Github. EmbedXSB me permitió
incluír los 50 niveles originales de Sokoban en Sokoban 4k.
La segunda se llama EmbedDIBits. Lee imágenes en formato PNG, BMP, JPG...
y crea cabeceras de C con un array de bytes que contiene el color de cada
pixel, en formato: 0xAARRGGBB, 32 bits. La idea es poder tomar los sprites
originales de Sokoban y tenerlos directamente en C, sin ningún tipo de archivo
intermedio.
Python
En su momento escribí EmbedXSB y EmbedDIBits en Python 2. EmbedDIBits usaba
PIL para leer las imágenes. Con el tiempo, porté EmbedDIBits a Python 3
y cambié de PIL a Pillow, dado que PIL lleva años sin actualizarse y no
soporta Python 3.
Mi experiencia con el lenguaje y las librerías es excelente. Cosas como parsear
opciones de línea de comandos (en plan "--help" o "--option bla") son muy fáciles
de hacer con argparse. Construcciones como "with open(...)", que cierran
automáticamente un archivo tras utilizarlo, son prácticas. Portar de Python 2
a Python 3 fue trivial, aunque también es cierto que EmbedDIBits es un programa
muy pequeño y simple.
De quejarme de algo sería de la conversión automática de finales de línea
dependiendo de la plataforma actual en la que se ejecuta el código:
# texto\n en Unix
# texto\r\n en Windows
# texto\r en Mac OS
print(texto)
# el final de línea que quieras, pero ha de ser en bytes:
eol = b'\n'
sys.stdout.buffer.write(bytes(texto, "utf-8") + eol)
Me quejo porque tengo la costumbre de permitir al usuario especificar cualquier
final de línea que desee ("--newline formato" en EmbedDIBits). Mi opinión es que
un programa realmente portable debe comportarse igual en todas las plataformas
y la salida que produce ha ser idéntica y reproducible.
Utilidades de consola
Quizá la mejor lección que aprendí de EmbedDIBits es a respetar y tener en cuenta
todo aquello que un usuario experimentado espera del comportamiento de un programa
de consola. Algunos ejemplos al respecto:
- Usa el programa stdout/stderr correctamente?
- Provee --help? Son el resto de opciones fáciles de entender por su descripción?
- Si produce archivos... puede imprimir su salida también por stdout?
- Puede redirigirse su stdout/stderr fácilmente?
- Está pensado para combinarse con otras herramientas? (por ejemplo: grep)
- Devuelve 0 o otro valor al terminar dependiendo de si ha habido errores?
- Entiende nombres de archivos con espacios? con carácteres UTF-8?
- Si la tarea que ha de realizar es larga: provee feedback adecuado al usuario?
- Tiene alguna opción para suprimir estos mensajes cuando no son necesarios?
Hay mucho más detrás de lo que parece (para variar) y es fácil olvidarse
de las cosas. Ahora, cada vez que empiezo un programa nuevo, reviso todo esto
y me guío por los que ya he hecho para mantener un standard aceptable.
Conclusiones
Lo que más me llama la atención de todo esto es que un proyecto relativamente
pequeño, como Sokoban 4k, puede dar lugar al nacimiento de otros 3 proyectos más.
Este patrón se ha vuelto común en mí. Es además una manera cómoda de testear
bien mis librerías, programas, etc..., porque cada proyecto depende de otros.
Al final todos se testean mutuamente.
Repositorios en Github: EmbedDIBits
Cosas que aprendí de... 4k
Me he mudado hace unas semanas. El caso es, que con todo el trajín, mis proyectos
han pasado a un segundo plano. Como también tengo este blog un tanto abandonado,
creo que un buen modo de volver a retomarlos es escribir unos cuantos post acerca de
ellos. Hablar de las cosas que salieron bien y las que no tan bien, decisiones de
diseño, etc...
Sokoban
Hace ya un par de años, escribí un clon de Sokoban en C. La idea era hacerlo
en 4 kilobytes (un .exe de no más de 4096 bytes) al estilo de lo que hacen los
grupos en la Demoscene o la gente de Java4k.
Sokoban es un juego con unas reglas extremadamente simples, así que parecía el
candidato ideal. El producto final, aunque sin sonido, tenía gráficos decentes
(con la paleta CGA de Sokoban de MS-DOS) y los 50 niveles originales. Recuerdo
la experiencia como frustrante, intentando sacar bytes de cualquier parte,
pero divertida.
Una anécdota es que el código de dibujar el nivel y el de comprobar si se ha
resuelto estaba mezclado en un solo bucle y ambos se hacían a la vez.
Una base común
Tras escribir Sokoban pensé que algo útil sería tener un framework, una especie
de plantilla con una base común reutilizable para demos o juegos de 4 kb. En un
alarde de originalidad, decidí llamar al proyecto... 4k.
Lo primero que aprendí es que es difícil definir una base común.
Los juegos necesitan control de teclado y ratón, las demos no. Las demos suelen
verse a pantalla completa, los juegos en una ventana. Para un juego simple, 2D
via GDI es más que suficiente, las demos a menudo usan OpenGL o DirectX.
Al final, definí la base común como:
- Crear una ventana con una resolución arbitraria.
- Un bucle (game loop) que funcione a una velocidad constante.
- Poder dibujar en la ventana con doble buffer.
Muchos juegos (especialmente los que caben en 4k), son más cómodos en ventana.
A pantalla completa, hay que preocuparse además de cosas como el aspect ratio
o la tasa de refresco de cada monitor. Aunque ambos pueden autodetectarse
decidí escoger el camino más simple.
El bucle es también el más simple posible. Se asume que todo PC puede ejecutar
la demo a la tasa de frames requerida sin problemas de rendimiento. Ni siquiera
se separa la lógica/renderizado, todo se actualiza a la misma velocidad. Para un
ejemplo de lo que puede complicarse un gameloop, lee Fix Your Timestep!. En
la práctica, para juegos sencillos, el bucle más simple es perfectamente usable.
Decidí no añadir nada para controlar el teclado. En ese punto... ¿por qué no ratón
y joystick?. Muchas demos no necesitan ninguno de ellos. Muchos juegos solo usan
uno de entre todos.
Finalmente, en lugar de hacer una plantilla, hice dos: una GDI y otra OpenGL.
Sin librería standard
En 4k no hay suficiente espacio para usar la librería de C. No hay malloc()
o rand(). Lo cierto es que no tener ninguna de estas funciones no
supuso un problema, ni en las demos de ejemplo que hice para 4k ni en Sokoban.
Normalmente, recrear lo que se necesita es fácil.
De elegir algo problemático, sería lo de siempre: C. Cada vez estoy más
convencido de que usar lenguajes donde un error puede pasar completamente
inadvertido es una mala idea, incluso para programas tan pequeños como 4k.
Tener excepciones también ayudaría a que el código que controla errores
no fuese tan extremadamente repetitivo al tener que comprobar manualmente
cada valor de retorno.
Algo que lo que sin embargo no me quejo es de la API de Windows (al menos de
las partes que he usado para 4k). Está bien documentada, es razonablemente
simple y funciona. Xlib es mucho más coñazo.
Tampoco me quejo de la portabilidad entre compiladores y arquitecturas.
El código compila sin cambios en todas las versiones que he podido testear
de MSVC, GCC y Clang, tanto en 32 como en 64 bit.
Demos
No había mejor modo de testear 4k que usándolo para hacer una demo simple.
En ambos casos (GDI y OpenGL), elegí algo que pudiese crearse combinando
las cosas más primitivas de la API: rectángulos en GDI, cubos en OpenGL.
Otra de las restricciones era que la demo debería funcionar correctamente
a cualquier tamaño de ventana y a cualquier tasa de frames por segundo, lo
que haría más fácil testear.
Conclusiones
Lo que pasa por mi cabeza al recordar el proyecto es que me parece increíble
que haga falta tanta historia para dibujar unos cuantos rectángulos.
Creo que si hubiese nacido en el 2000, nunca habría aprendido a programar.
Los sistemas operativos ya no incluyen herramientas para ello por defecto.
Falta esa inmediatez de tener siempre un QBasic a mano para trastear, donde
hacer el equivalente a 4k-example son unas 10 líneas.
Es cierto que hoy los sistemas operativos y en general los programas hacen
cosas mucho más complejas que entonces. Hemos avanzado una barbaridad. Quizá
sea la nostalgia, pero tengo la sensación de que en algún punto entre todo este
progreso, se perdió algo importante.
Repositorios en Github: 4k - 4k-Example - 4kGL - 4kGL-Example